首先,安裝下面這些要用到的 library。
|
library(ggplot2) library(dplyr) library(hexbin) data(diamonds) data(mpg) |
用點的大小或深淺來表現是什麼意思呢?我們同樣用檔案資料 mpg 來舉例,假設我們要看 class 和 cty 的關係,先用 xtabs() 功能來看看。
xtabs() 是 cross tabulation,是用來看一個 variable 裡面的分佈,或是用來看兩個 variables 之間的關係。
如果想看某個 variable 裡面的分佈,語法是:xtabs(~ var1, data)
我們可以先來看看 class 裡面的分佈。
| xtabs(~ class, mpg) |
| class 2seater compact midsize minivan pickup subcompact suv 5 47 41 11 33 35 62 |
會顯示出 2seater 有五個,compact 有 47 個,minivan 有十一個等等。
如果想看兩個 variables 之間的關係的話,語法是這樣:xtabs(~ var1 + var2, data)
例如想看 cty 和 class 之間的關係,也就是 class 裡面各種車型裡 cty 的分佈情形。
| xtabs(~ cty + class, mpg) |

從上面的表格可以看到 2seater 的五個裡面,cty = 15 的有三個,cty = 16 的有兩個。
接下來,我們可以用點圖來表現。
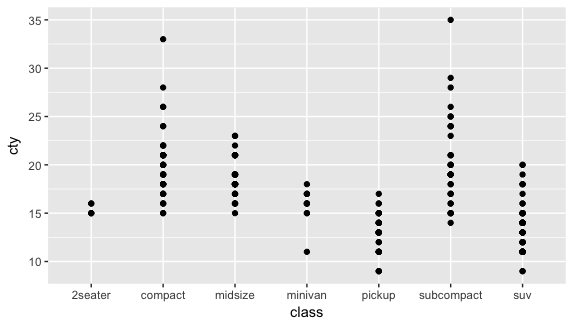
| ggplot(mpg, aes(class, cty)) + geom_point() |
如果想把點變小,可以這樣:(不過在這個例子裡把點變小沒什麼特別的意義)
| ggplot(mpg, aes(class, cty)) + geom_point(shape = '.') |

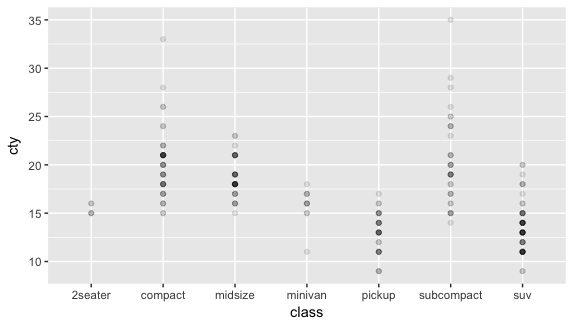
可以把上面的表和圖做對照,例如在 2seater 裡面有兩種 cty, 15 的有三個,16 的有兩個。不過在上圖看不出來 15 的比 16 的多,這時我們可以讓點依數量而深淺(或透明度)不同,用的語法是在 geom_point() 裡面加入:alpah = 1/n(分母越大越透明)
|
ggplot(mpg, aes(class, cty)) + geom_point(alpha = 1/10) |
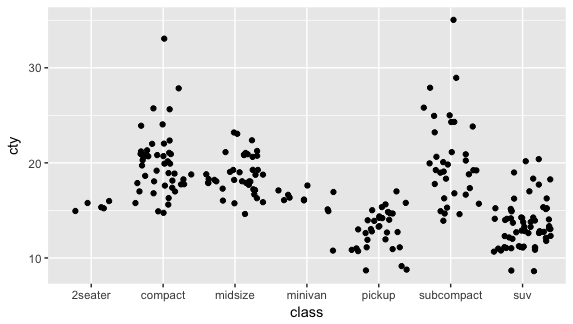
除了用點的深淺或透明度呈現每個點的大小外,也可以用 geom_jitter()。當每個點有一個以上的量時,jitter 會用把它隨機分散。例如上面 2seater 裡的 15 有三個,在點圖上只呈現一個點,但在 jitter plot 上面會呈現出三個點。
|
ggplot(mpg, aes(class, cty)) + geom_jitter() |
geom_jitter() 原本是下面這樣,後來簡化成上面那樣。
|
ggplot(mpg, aes(class, cty)) + geom_point(position = 'jitter') |
可以看到 2seater 的 15 和 16 那附近有兩、三個點,但是因為預設值太分散了,所以分不清楚,這時我們可以設定其散落的範圍,例如把垂直移動(散落)的範圍設為 0,如此就能區分出 cty 的每個點,像是可以把 15 和 16 分開。
|
ggplot(mpg, aes(class, cty)) + geom_jitter(width = 0.2, height = 0) |

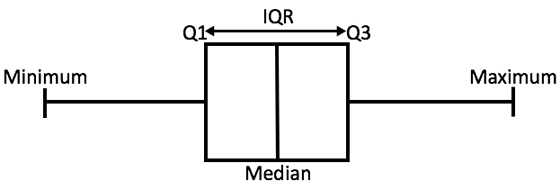
也可以和 box plot 重疊。Box plot 的中間那一條是 medium (中間值,不是平均值),就是一個數列中,中間的那一個。上面那條線代表數列中的 25th percentiles (百分位),也就是中間值到最大值間的中間值,叫 Q3;下面那條線則是數列中的 75th percentiles,就是中間值到最小值間的中間值 ,叫 Q1。Q1 和 Q3 之間的距離,也就是 Q3-Q1,叫做 IQR (interquartile range)。(還是不懂的可以看這個影片)
Box plot 的上下會有兩條鬚鬚,叫 whisker。它的長度在 R 裡的預設是 1.5,也就是:
max: Q3 + 1.5 * IQR
min: Q1 - 1.5 * IQR
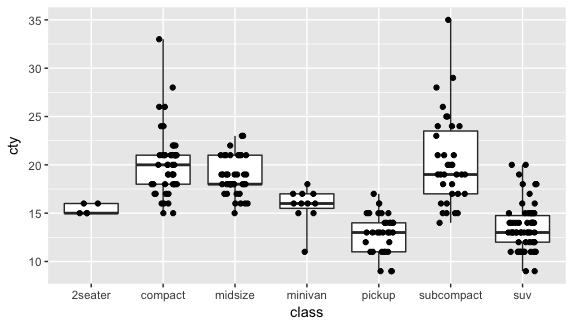
我們先來看看 whisker 的預設是 1.5 是長怎樣(用預設的意思就是沒特別去設定),同時也把 outlier 設了顏色和形式,看看圖會變成怎樣。
|
ggplot(mpg, aes(class, cty)) + geom_boxplot(outlier.colour = "red", outlier.shape = 1) + geom_jitter(width = 0.2, height = 0) |

outlier.shape = 的語法裡: 0 = square, 1 = circle, 2 = triangle
設定 whisker 長度的語法是:coef =
如果沒設的話就是 1.5 (如上圖)。如果設 coef = 0 的話,就是沒有那兩條鬚鬚。如果設為 coef = NULL,鬚鬚就會延伸到最大值和最小值。
|
ggplot(mpg, aes(class, cty)) + geom_boxplot(coef = NULL) + geom_jitter(width = 0.2, height = 0) |
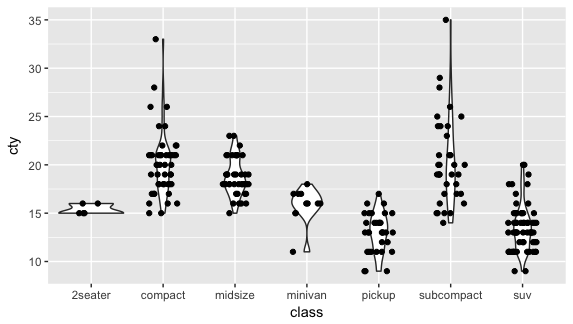
或是和 violin plot 重疊,之前因為覺得這種圖用不上,所以沒介紹,不過在這邊可以和 jitter plot 重疊看看。
|
ggplot(mpg, aes(class, cty)) + geom_violin() + geom_jitter(width = 0.2, height = 0) |
再來,我們換特別的圖:geom_bin2b()
|
ggplot(mpg, aes(class, cty)) +
geom_bin2d() |
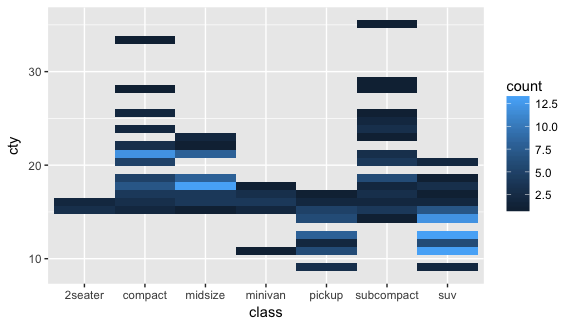
這個跟點圖的透明度類似,用顏色的深淺區分那個點的 count 有多少。
現在視覺話很夯,我們也可以用其他特別的圖來做視覺話,例如六角形的點。這個圖需要用到 library(hexbin)。
在這個圖裡,我們把 class 裡面的 2seater 的資料拿掉,把拿掉後的資料設為 mpg_df。如果你還記得的話, != 是指不等於,在這裡我們用 filter() 挑出 class 不是 2seater 的資料。
| mpg_d1 <- filter(mpg, class != '2seater') |
再用 mpg_df 來畫圖。
|
ggplot(mpg_d1, aes(class, cty)) + geom_hex() |
也可以用 %>% 把上面兩個合在一起。(這邊看不懂的話,請看這篇。)
| ggplot(mpg %>% filter(class != '2seater'), aes(class, cty)) + geom_hex() |
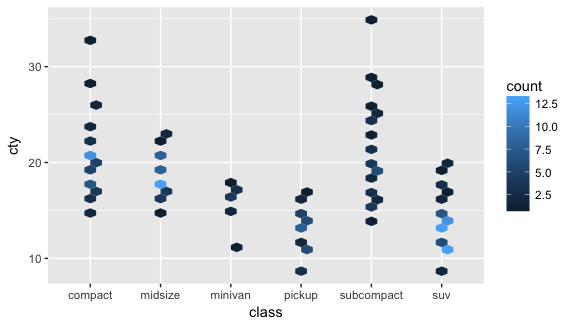
最後,來做個練習。
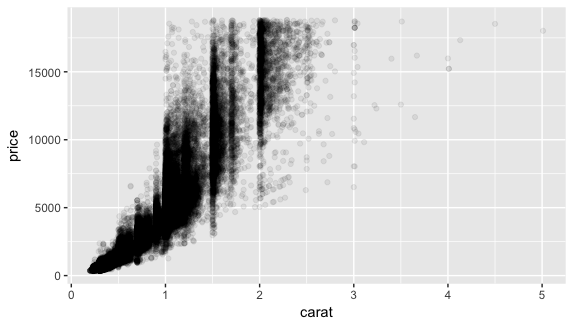
Visualize the relationship between weight and price of the diamond in the “diamonds” dataset. Try the strategies we’ve just discussed to deal with overplotting.
|
ggplot(diamonds, aes(carat, price)) + geom_point(alpha = 1/15) |
也可以這樣畫。
|
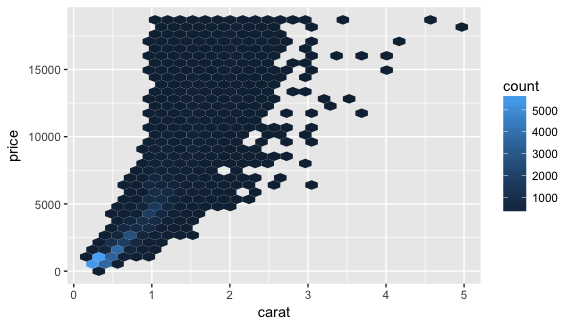
ggplot(diamonds, aes(carat, price)) + geom_hex() |